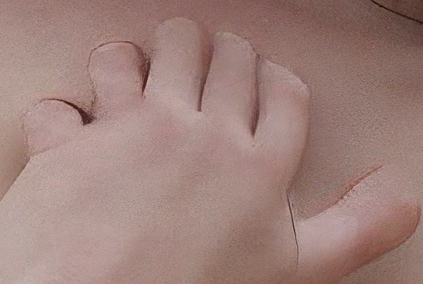
There are sometimes days where the gods of SD are just mocking you. That hand was made from a depth map extracted from a real human pose, and the map very clearly show FOUR FUCKING FINGERS. And yet...
I am starting to wonder if this model was trained exclusively on people with polydactyly. If so, well played internet.
I have tried a bunch of stuff to get good hands and feet from SD, and nothing is even slightly reliable. TI and negative prompts sometimes just don't work, or even make stuff worse. Inpainting takes forever to make work well. I thought controlnet would crack it but apparently not.
How do you guys deal with dodecadactyl mutants?
It does seem to work fairly well, although I will say that it doesn't fit my workflow at all so I haven't done a lot of testing. I do think there are some UI things that you could look at though. Engine and Dimensions shouldn't be minimizable lists, because the fields only take up as much space as the label does. Also, your tooltips are outrageously large, covering about 75% the width of a 1080p monitor which makes them quite hard to actually read.