11
Haha I'm to late :( Not available anymore. You sure it isn't about the external player used by jellyfin on mobile?
Cauz' I remember I had issues with .ASS subtitles only on mobile when VLC was used as external player.
Haha I'm to late :( Not available anymore. You sure it isn't about the external player used by jellyfin on mobile?
Cauz' I remember I had issues with .ASS subtitles only on mobile when VLC was used as external player.
I hope this is a smooth release, I do not want to bork my EndeavourOS. It took so much time to customize it to my personal taste !!
Ohhh? I tried to make it work even adding the certificate into de /data folder of MPV (rooted android) but it didn't worked... (source)
I remember I even checked the logs via ADB and while I can't remember the exact error logs, it wasn't accepting my certificate.
Also android MPV is the only application on Android that doesn't accept my self-signed certificate. Navidrome, HTTP shortcuts, bitwarden, Tempo... They all accept without any problems.
If you have some juicy info to share I'm all ears 👍 !!
Edit: It's probably related to android 14 (god I hate it here...) But can't revert to 13... The Stock firmware builds are Bitwise different.
Being able to stream my shows on an unstable or lower bandwidth internet connection like on a train
Oh yeah good point wasn't thinking of that kind of use case. Internet is available everywhere now and I'm so used to gigabit Ethernet and high-speed WiFi/5g that I forgot the low speed of public WiFi or locations where the connection can get unstable.
You could argue I should adapt my habits to my means but I frankly really think it should be the other way around, and transcoding solves that for me.
In the past I probably would ^^" but today it's nearly impossible if you want a balanced life in a daily working/study routine. There's so much to do, to much to think of, to much information... Automating stuff is where you can gain hours in the long run, so I totally get it !
Thanks for your answer !
What kind of stylized subtitles? I do not have a big library so I have never encountered this kind of trouble. But I'm curious to know to circumvent in advance.
Most anime have .ASS subtitles and are kinda complex sometimes with singsong related subtitles, but never had any issues on android with them.
And most movies have simple plain text subtitles.
Just a personal use case, maybe it isn't an advantage. But the official android app is just a web wrapper and the use of MPV as external player don't allow self-signed local certificates (and they never will...).
Findroid does the job for you while using MPV under the hood and you can connect to your local DNS with self-signed certs without any issues :).
May I ask why? Maybe I haven't been in your actual case so I probably can't relate.
However having everything in a format that every device can read and disable transcoding on jellyfin, saves resources and power usage.
Yeah maybe I got so used to SSD's that I can't remember the leap between SSD's and HDD's.
An as you said the difference between M.2 isn't that much of a difference in game. There probably lies my bias.
Yep ! No-ads, no-sponsor, no-shit.
You even don't need to self-host, just disable piped proxy, enable local extraction, use HLS and a good VPN.
Sure it's not as anonymous and sometime I need to disable my VPN, but that's only temporarily, until they find a new loophole in youtoube's api.
That's not piped nor invidious backend's fault, just YouTube doing his cat and mouse thing...
Someone a short ELI ? I read the article and the comments... But I have no idea what this is about.
Maybe someone has an article that explains for someone not being educated as computer scientist ?
For those interested, John Hammond did a video a few months ago about .lnk extension (and other 16 hidden extensions on Windows).
He doesn't go to much or to deep into the subject, but you get a general view how this could be exploitable.
cross-posted from: https://lemmy.ml/post/15968883
Hello everyone ! Nobody seems to have an answer on !networking@sh.itjust.works (or maybe they are not interested because it's an enteprise network community?) and !homenetworking@selfhosted.forum seems dead?
Anyway, If anyone could guide me or direct me to the right direction, I would really appreciate it !
TL:DR
What is encapsulated into the frame that makes everyone understand: "OHHH that’s for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Hi everyone !
I'm scratching my head in finding an actual answer on how virtual networking in docker actually works (mostly on the packets/frame level) or some good documentation to improve my understanding on how everything fits together.
Because I'm probably lacking the correct network terminology I made a simple network topology of my network. Don't hesitate to correct any network mistake.
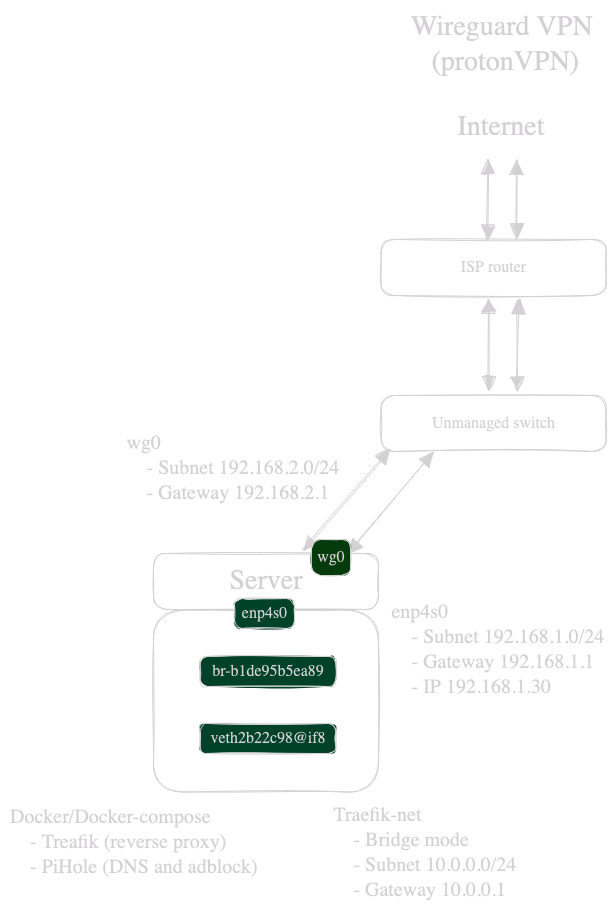
In my scenario, my docker container with the virtual interface veth2b22c98 and the following ip (10.0.0.8) connects to bridge network br-b1de95b5ea89. When I curl, from my conntainer, lemmy.ml the packets/frame is send to my enp4s0 and goes through my wireguard tunnel to my VPN provider which sends back the packet/frame/handshake...
I probed every interface with tcpdump (enp4s0, wg0, br-b1,veth2b):
enp4s0: Every packet/frame is encapsulated into the wireguard protocol with my physical interface's IP (192.168.1.30) and no DNS is visible on that interface (like expected) and sends it out to my ISP's public IP.
wg0: Shows every packet/frame with the actual protocol with my wireguard's interface IP (192.168.2.1) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
br-b1: Shows every packet/frame with the actual protocol with my containers IP (10.0.0.8) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
I know there is a mix of 2 different concepts in my scenario (wireguard tunnel and virtual networking) but I really do not understand how the frame gets back to my docker container. When I look at the frames on wg0, there is no mention of either the MacAddress of my container or the actual IP of my container.
How/when/what ? is exactly happening to my frame so that it gets to the correct target between my physical interface, virtual interface, bridge ? I mean with VLAN's there's a VLAN tag on the frame, so you can easily identify with Wireshark where it should go. But here, I cannot find any clue who or what is doing the magic so the frame finds it's way back to my docker container.
What is encapsulated into the frame that makes everyone understand: "OHHH that's for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Sorry for my broken English and lack of networking terminology and thank you for those who beared with me and are willing the give me some hints/proper networking lesson.
Edit: Whoops I just read that networking@sh.itjust.works is for enterprise networks? I hope my small homelab question doesn't break the rules? If so I will redirect my question.
Hi everyone !
I'm scratching my head in finding an actual answer on how virtual networking in docker actually works (mostly on the packets/frame level) or some good documentation to improve my understanding on how everything fits together.
Because I'm probably lacking the correct network terminology I made a simple network topology of my network. Don't hesitate to correct any network mistake.
In my scenario, my docker container with the virtual interface veth2b22c98 and the following ip (10.0.0.8) connects to bridge network br-b1de95b5ea89. When I curl, from my conntainer, lemmy.ml the packets/frame is send to my enp4s0 and goes through my wireguard tunnel to my VPN provider which sends back the packet/frame/handshake...
I probed every interface with tcpdump (enp4s0, wg0, br-b1,veth2b):
enp4s0: Every packet/frame is encapsulated into the wireguard protocol with my physical interface's IP (192.168.1.30) and no DNS is visible on that interface (like expected) and sends it out to my ISP's public IP.
wg0: Shows every packet/frame with the actual protocol with my wireguard's interface IP (192.168.2.1) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
br-b1: Shows every packet/frame with the actual protocol with my containers IP (10.0.0.8) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
I know there is a mix of 2 different concepts in my scenario (wireguard tunnel and virtual networking) but I really do not understand how the frame gets back to my docker container. When I look at the frames on wg0, there is no mention of either the MacAddress of my container or the actual IP of my container.
How/when/what ? is exactly happening to my frame so that it gets to the correct target between my physical interface, virtual interface, bridge ? I mean with VLAN's there's a VLAN tag on the frame, so you can easily identify with Wireshark where it should go. But here, I cannot find any clue who or what is doing the magic so the frame finds it's way back to my docker container.
What is encapsulated into the frame that makes everyone understand: "OHHH that's for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Sorry for my broken English and lack of networking terminology and thank you for those who beared with me and are willing the give me some hints/proper networking lesson.
Edit: Changed something on my network diagram (wireguard is not in a container it's bare bone on the server) and some typo.
After the discussion in the following post I dug a bit deeper the rabbit hole.
While I mostly relied on Exodus to see if an app has trackers in it... I was baffle to see all the sketchy requests it made while dumping the DNS requests with PCAPdroid...
Over 200 shady requests in a few seconds after login... here's a preview:

While I don't use AdguardVPN, I have Adguard Home as my DNS server in my homelab... I think It's time to switch to pi-hole !
Edit: VPN pcapdroid


I have no idea what streamlabs or Android TV boxes uses as backend player, but after a lot of debugging MPV solved all my subtitles issues on mobile (android) and desktop (Linux).
It made me kinda sad because VLC was the defacto application I installed on Windows for years !! But since I'm on Linux, MPV is the new standard in my default applications.
Maybe have a look if you can change the default player?