On god
morrowind
joined 1 month ago
Link to bluesky https://bsky.app/profile/tomaarsen.com/post/3llc2jvwah22f
Some more details https://huggingface.co/blog/train-reranker

Thumbnail looks a little odd when small. You may want to go for a more digital llama aesthetic
12
NotaGen: Advancing Musicality in Symbolic Music Generation with Large Language Model Training Paradigms
(electricalexis.github.io)
autotracers can't generate svgs from text
Claude frequently draws svgs to illustrate things for me (I'm guessing it's in the prompt) but even though it's better at it than all the other models, it still kinda sucks. It's just fudamentally dumb task to do for a purely language model, similar to the arc-agi benchmark , just makes more sense for a vision model and trying to get an llm to do is a waste
what is the license? The link on hf just 404s
Very similar to chain of draft but seems more thorough
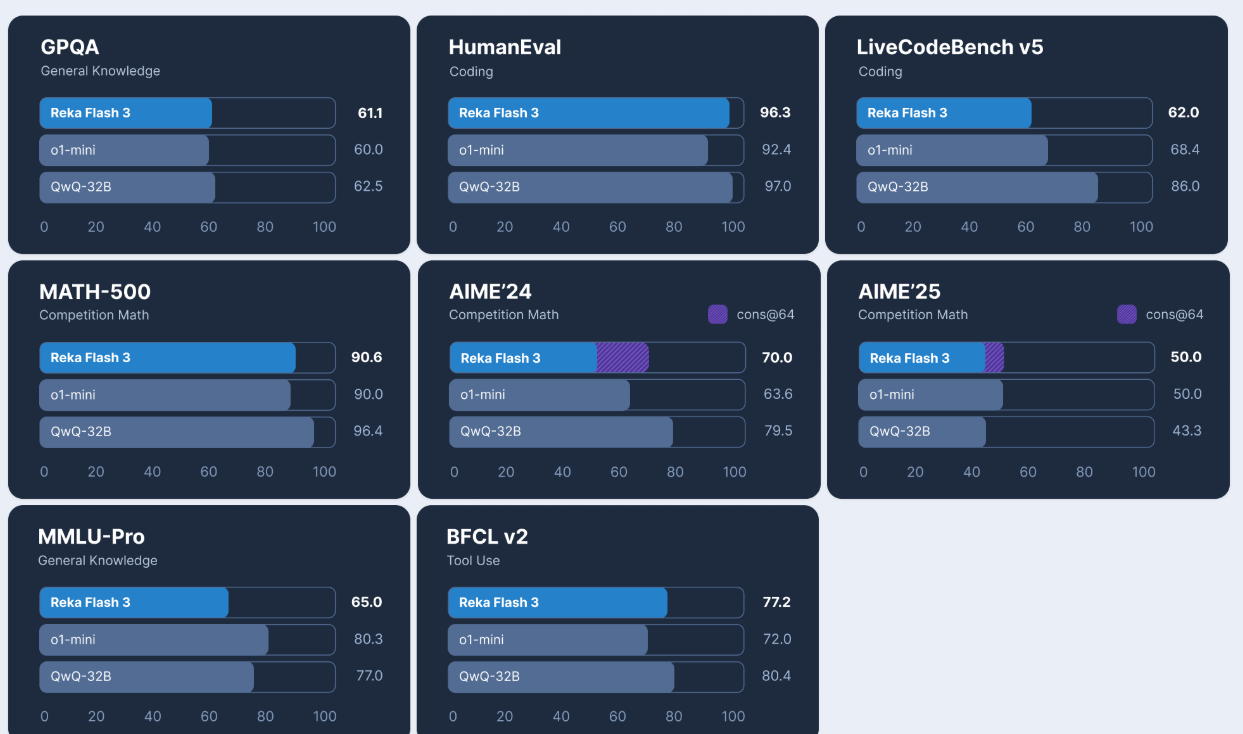
It matches R1 in the given benchmarks. R1 has 671B params (36 activated) while this only has 32
insane, absolutely insane
good luck trying to run a video model locally
Unless you have top tier hardware
view more: next ›
I want to clarify something. Reranker is a general term that can refer to any model used for reranking. It is independent of implementation.
What you refer to
Is a specific implementation known as CrossEncoder that is common for reranking models but not retrieval ones for the reasons you described. But you can also use any other architecture