26
Machine Learning
568 readers
1 users here now
A community for posting things related to machine learning
Icon base by Lorc under CC BY 3.0 with modifications to add a gradient
founded 2 years ago
MODERATORS
27
28
29
30
8
Image denoising techniques: A comparison of PCA, kernel PCA, autoencoder, and CNN
(www.fabriziomusacchio.com)
31
32
33
34
35
36
37
38
39
40
41
42
19
Real World Data Science Competition | When will the cherry trees bloom?
(realworlddatascience.net)
43
44
6
The Random Transformer | Understand how transformers work by demystifying all the math behind them
(osanseviero.github.io)
45
cross-posted from: https://programming.dev/post/8391233
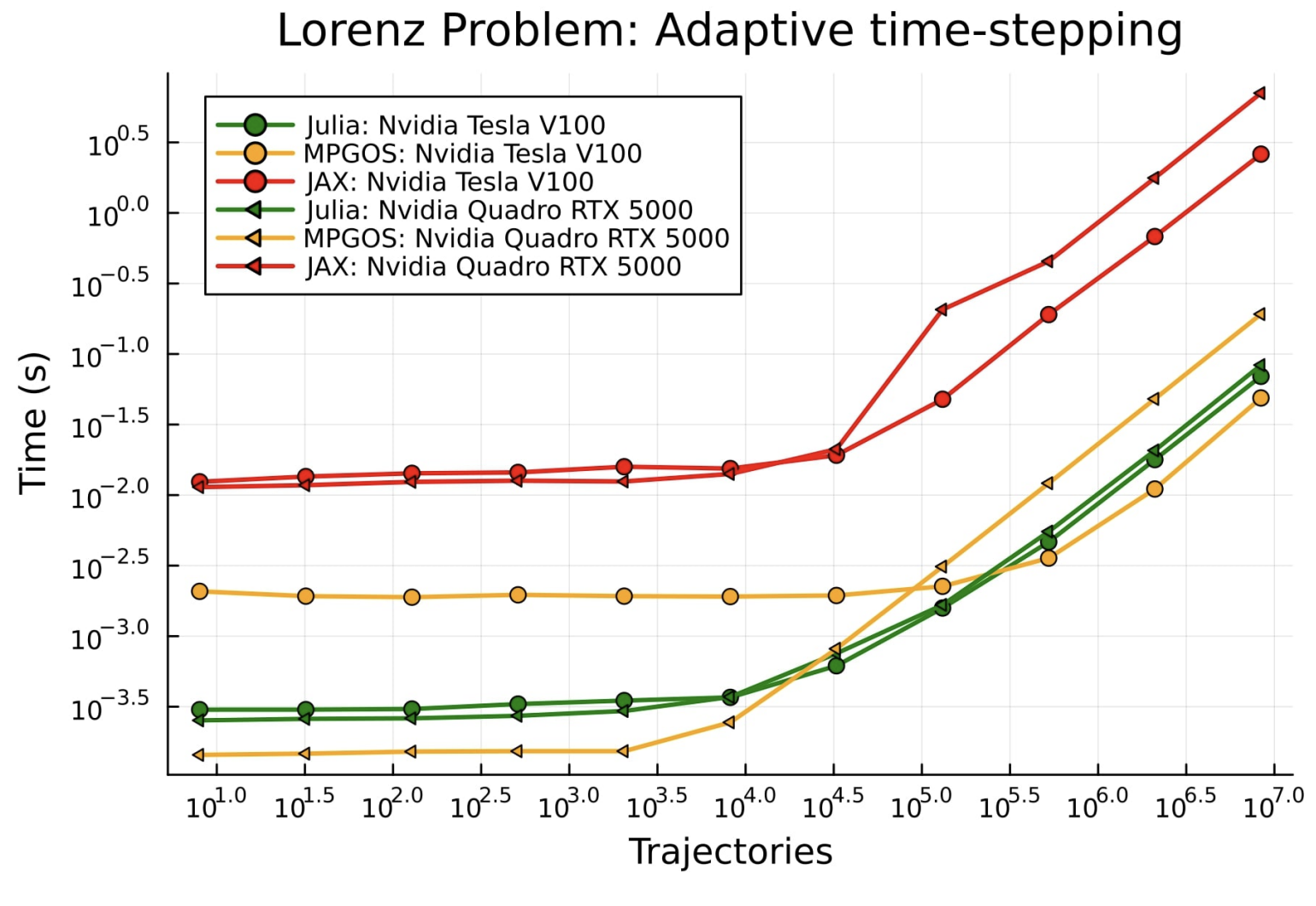
Dr. Chris Rackauckas (@chrisrackauckas@fosstodon.org) writes:
#julialang GPU-based ODE solvers which are 20x-100x faster than those in #jax and #pytorch? Check out the paper on how #sciml DiffEqGPU.jl works. Instead of relying on high level array intrinsics that #machinelearning libraries use, it uses a direct kernel generation approach to greatly reduce the overhead.
Read Automated translation and accelerated solving of differential equations on multiple GPU platforms
46
47
3
Sentence Embeddings | Everything you wanted to know about sentence embeddings (and maybe a bit more)
(osanseviero.github.io)
48
49
50