1
Machine Learning
613 readers
1 users here now
A community for posting things related to machine learning
Icon base by Lorc under CC BY 3.0 with modifications to add a gradient
founded 2 years ago
MODERATORS
2
3
1
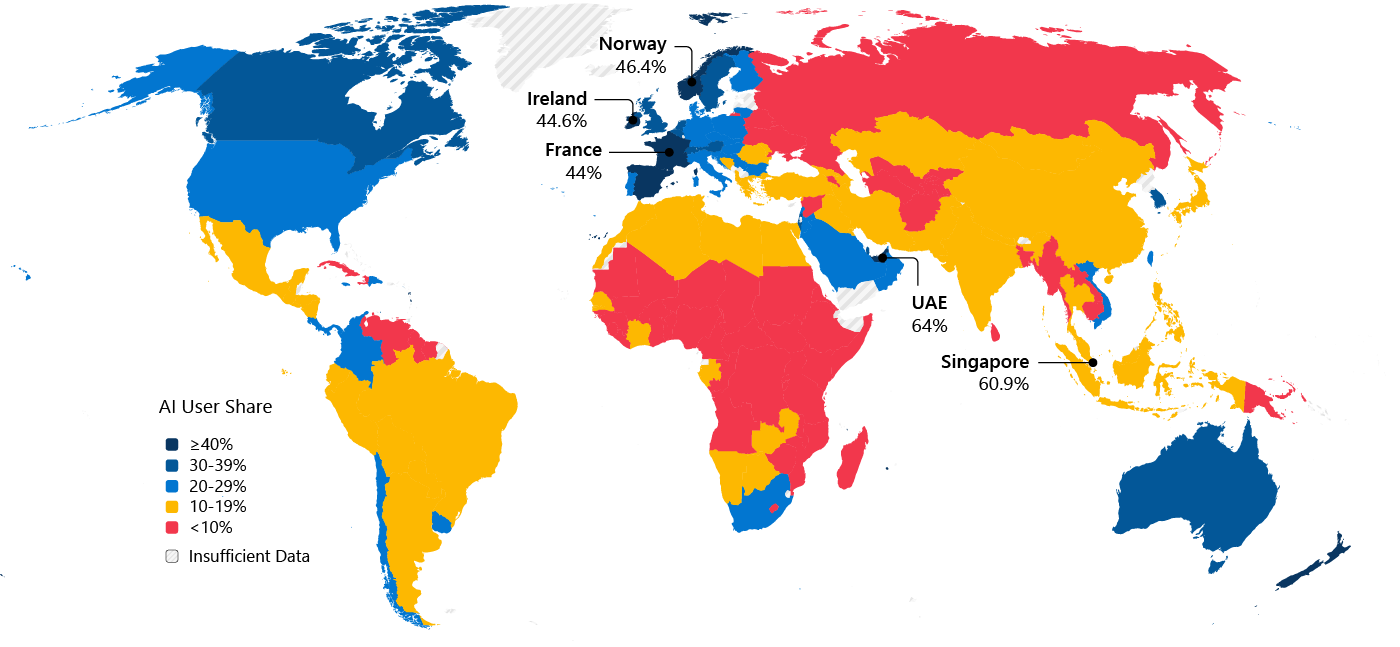
12% of American workers use artificial intelligence in their roles every day
(sherwoodnews.imgix.net)

4
5
6
7
8
9
10
11
12
13
14
15


18
19
20
21
22
-1
Evaluation of large language model (LLM) to generate efficient Solidity code
(opensource.orange.com)
23
24
25
8
Learn PyTorch for Deep Learning: Zero to Mastery | Free Online Book | Daniel Bourke
(www.learnpytorch.io)
view more: next ›