April is here and we're still enjoying our little corner of the lemmy-verse! This post is quite late for our April announcement as my chocolate coma has only now subsided
Donations
Due to some recent huge donations recently on our Ko-Fi we decided to migrate our database from our previous big server to a dedicated database server. The idea behind this move was to allow our database to respond faster with a faster CPU. It was a 3.5GHz cpu rather than what we had which was a 3.0GHz. This, as we know, did not pan out as we expected.After that fell through we have now migrated everything to 1 huge VPS in a completely different hosting company (OVH).
Since the last update I used the donations towards setting up an EU proxy to filter out down votes & spam as a way to try and respond faster to allow us to catch up. We've purchased the new VPS from OVH (which came out of the Ko-Fi money), & did the test of the separate database server in our previous hosting company.
Our Donations as of (7th of April):
- Ko-Fi: $280.00
- OpenCollective: $691.55 (of that 54.86 is pending payment)
Threads Federation
Straight off the bat, I'd like to say thank you for those voicing your opinions on the Thread federation post. While we had more people who were opposed to federation and have since deleted their accounts or moved communities because of the uncertainty, I left the thread pinned for over a week as I wanted to make sure that everyone could respond and have a general consensus.
Many people bought great points forward, and we have decided to block Threads. The reasoning behind blocking them boils down to:
- Enforced one-way communication, allowing threads users to post in our communities without being able to respond to comments
- Known lack of Moderation which would allow for abuse
These two factors alone make it a simple decision on my part. If they allowed for comments on the post to make it back to a threads user then I probably would not explicitly block them. We are an open-first instance and I still stand by that. But when you have a history of abusive users, lack of moderation and actively ensure your users cannot conduct a conversation which by definition would be 2 way. That is enough to tip the scales in my book.
Decision: We will block Threads.net starting immediately.
Overview of what we've been tackling over the past 4 weeks
In the past month we've:
- Re-configured our database to ensure it could accept activities as fast as possible (twice!)
- Attempted to move all lemmy apps to a separate server to allow the database to have full use of our resources
- Purchased an absurd amount of cpus for a month to give everything a lot of cpu to play with
- Setup a haproxy with a lua-script in Amsterdam to filter out all 'bad' requests
- Worked with the LW Infra team to help test the Amsterdam proxy
- Rebuilt custom docker containers for added logging
- Optimised our nginx proxies
- Investigated the relationship between network latency and response times
- Figured out the maximum 3r/s rate of activities and notified the Lemmy Admin matrix channel, created bug reports etc.
- Migrated our 3 servers from one hosting company to 1 big server at another company this post
This has been a wild ride and I want to say thanks to everyone who's stuck with us, reached out to think of ideas, or send me a donation with a beautiful message.
The 500 mile problem (Why it's happening for LemmyWorld & Reddthat)
There are a few causes of this and why it effects Reddthat and a very small number of other instances but the main one is network latency. The distance between Australia (where Reddthat is hosted) and Europe/Americas is approximately 200-300ms. That means the current 'maximum' number of requests that a Lemmy instance can generate is approximate 3 requests per second. This assumes a few things such as responding instantly but is a good guideline.
Fortunately for the lemmy-verse, most of the instances that everyone can join are centralised to the EU/US areas which have very low latency. The network distance between Paris and Amsterdam is about 10ms. This means any instances that exist in close proximity can have an order of magnitude of activities generated before they lag behind. It goes from 3r/s to 100r/s
- Servers in EU<->EU can generate between 50-100r/s without lagging
- Servers in EU<->US can generate between 10-12r/s without lagging
- Servers in EU<->AU can generate between 2-3r/s without lagging
Already we have a practical maximum of 100r/s that an instance can generate before everyone on planet earth lags behind.
Currently (as of writing) Lemmy needs to process every activity sequentially. This ensures consistency between votes, edits, comments, etc. Allowing activities to be received out-of-order brings a huge amount of complexity which everyone is trying to solve to allow for all of us (Reddthat et al.) to no longer start lagging. There is a huge discussion on the git issue tracker of Lemmy if you wish to see how it is progressing.
As I said previously this assumes we respond in near real-time with no processing time. In reality, no one does, and there are a heap of reasons because of that. The biggest culprit of blocking in the activity threads I have found (and I could be wrong) is/was the metadata enrichment when new posts are added. So you get a nice Title, Subtitle and an image for all the links you add. Recent logs show it blocks adding post activities from anywhere between 1s to 10+ seconds! Since 0.19.4-beta.2 (which we are running as of this post) this no longer happens so for all new posts we will no longer have a 5-10s wait time. You might not have image displayed immediately when a Link is submitted, but it will still be enriched within a few seconds.
Unfortunately this is only 1 piece of the puzzel and does not solve the issue. Out of the previous 24hours ~90% of all recieved activities are related to votes. Posts are in the single percentage, a rounding error.
This heading is in reference to the 500 miles email.
Requests here mean Lemmy "Activities", which are likes, posts, edits, comments, etc.
So ... are we okay now?
It is a boring answer but we wait and enjoy what the rest of the fediverse has to offer. This (now) only affects votes between LemmyWorld to Reddthat. All communities on Reddthat are successfully federating to all external parties so your comments and votes are being seen throughout the fediverse. There are still plenty of users in the fediverse who enjoy the content we create, who interact with us and are pleasant human beings. This only affects votes because of our forcing federation crawler which automatically syncs all LW posts and comments. We've been "up-to-date" for over 2 weeks now.
It is unfortunate that we are the ones to be the most affected. It's always a lot more fun being on the outside looking in, thinking about what they are dealing with and theorising solutions. Knowing my fellow Lemmy.nz and aussie.zone were affected by these issues really cemented the network latency issue and was a brilliant light bulb moment. I've had some hard nights recently trying to manage my life and looking into the problems that are effecting Reddthat. If I was dealing with these issues in isolation I'm not sure I would have come to these conclusions, so thank you our amazing Admin Team!
New versions means new features (Local Communities & Videos)
As we've updated to a beta version of 0.19.4 to get the metadata patches, we've already found bugs in Lemmy (or regressions) and you will notice if you use Jerboa as a client. Unfortunately, rolling back isn't advisable and as such we'll try and get the issues resolved so Jerboa can work.
We now have ability to change and create any community to be "Local Only".
With the migration comes support for Video uploads, Limited to under 20MB and 10000 frames (~6 minutes)! I suggest if you want to shared video links to tag it with [Video] as it seems videos on some clients don't always show it correctly.
Thoughts
Everyday I strive to learn about new things, and it has certainly been a learning experience! I started Reddthat with knowing enough of alternate technologies, but nearly nothing of rust nor postgres. 😅
We've found possibly a crucial bug in the foundation of Lemmy which hinders federation, workarounds, and found not all VPS providers are the same. I explained the issues in the hosting migration post. Learnt a lot about postgres and tested postgres v15 to v16 upgrade processes so everyone who uses the lemmy-ansible repository can benefit.
I'm looking forward to a relaxing April compared to the hectic March but I foresee some issues relating to the 0.19.4 release, which was meant to be released in the next week or so. 🤷
Cheers,
Tiff
PS. Since Lemmy version 0.19 you can block an instance yourself without requiring us to defederate via going to your Profile, clicking Blocks, and entering in the instance you wish to be blocked.
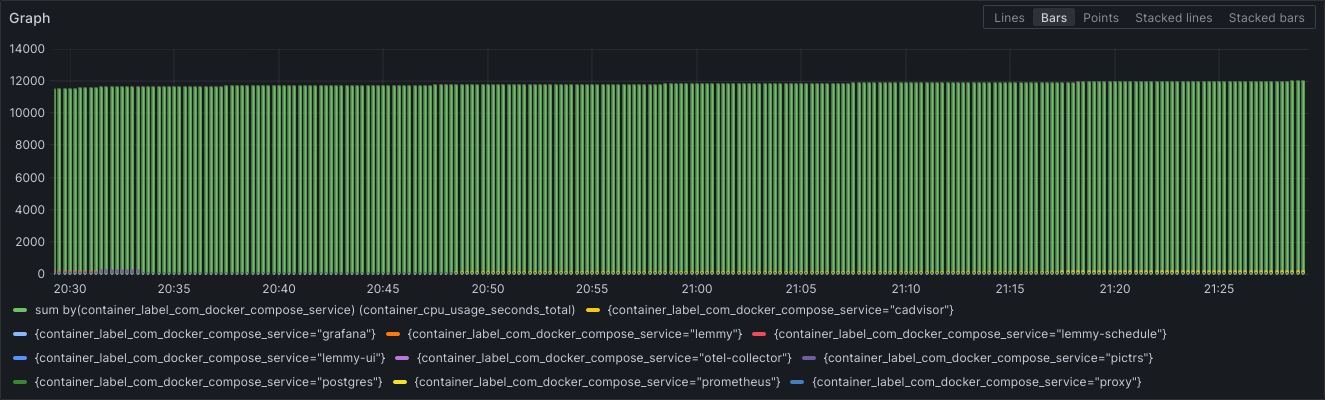
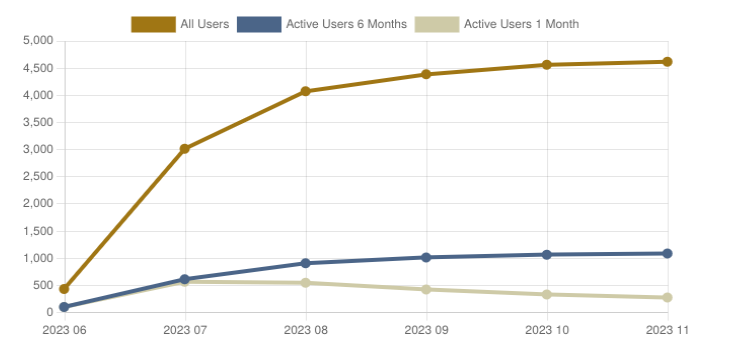
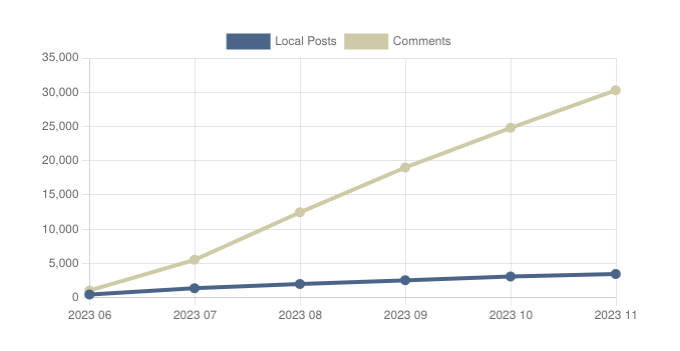
Fun Graphs:
Instance Response Times:


Data Transfers:



 ](
]( ](
](