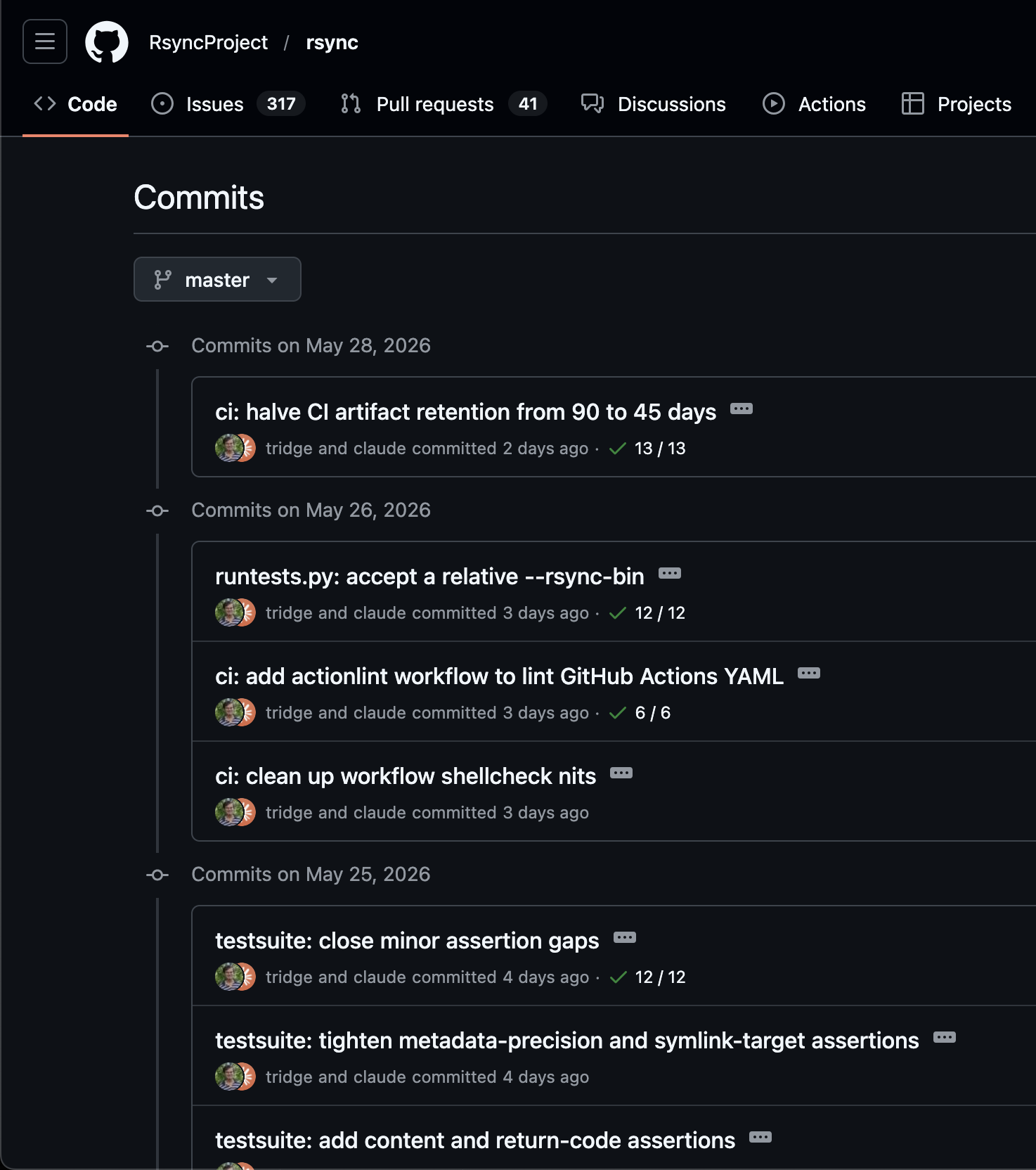
I looked at the rsync commit log and basically every commit since March says "tridge and claude committed." Andrew Tridgell, the guy who literally invented rsync in 1996. Now hes using a chatbot to write the code and proudly displaying its name right there in the commit.
And before anyone goes "calm down its just a typo fix" no. The recent stuff is the security fixes for 3.4.3. The symlink race CVEs.. You know, the exact part where you want an actual human who understands what hes doing, not a machine that spits out code that looks correct but has correctness errors.
Do you get how insane this is? Rsync is the thing holding up basically every backup system on earth. Your NAS uses it. Distro mirrors use it. The server with you grandmas photos uses it. And now the plan is to let a token predictor that can't even count the amount of letter R's in "strawberry" write code for it.
"But the tests pass." The tests pass because the AI probably wrote the tests too you walnut. Its a loop of confident nonsense thats grading its own homework, and the first time it hits an edge case nobody fed it its gonna silently corrupt something and noone notices till the backups are already poisoned.
I'm pinning v3.4.1 and not updating again. If you defend this, dont say nobody warned you when the data loss posts start appearing.