660
Ladies and Gentlemen, this is what slopperations are funneling all their money into in 2026
(files.catbox.moe)
"We did it, Patrick! We made a technological breakthrough!"
A place for all those who loathe AI to discuss things, post articles, and ridicule the AI hype. Proud supporter of working people. And proud booer of SXSW 2024.
AI, in this case, refers to LLMs, GPT technology, and anything listed as "AI" meant to increase market valuations.
what the fuck is up with this sub and people USING AI to "prove how dumb it is"?? you don't need to use AI to come to that conclusion. do you have any idea the scale of resources you and ppl like you are wasting just to make your stupid fucking point? this isn't a fuck AI sub it's just a place where people who very much use AI complain that it isn't good enough
As long as people are not paying to use them, I say use them as much as you want.
This will just make the AI companies run out of money quicker.
If you don't use that, then a paying user will use it anyway, which is worse.
That very short examples aren't that burdensome, the real resource load hits on generating videos or anything where it might go off for several minutes, or make paragraphs.
The problem with refraining from using it and saying "well obviously it sucks" is that folks don't believe. They say "yeah, well, that night have been how ChatGPT 8.1 was., but it probably works fine with ChatGPT 8.2". The narrative is eternally "we were broken but fixed it all in our new version", and without ongoing examples, they get to own the narrative and critics are just "luddites".
Hell someone was saying how awesome Gemini was at codegen, so I showed it totally screwing up to the folks. Someone said "well, honestly, Gemini sucks for code, but Opus 4.6 is incredible.". So a few days later I bother to do a similar example with opus 4.6. some guy in the room said "well, actually Gemini is better than opus for coding". These people are absurd....
this isn’t a fuck AI sub
It's literally called "Fuck AI" though, so you can't blame people for being confused.
i think he means that its a bit pointless to nitpick little things like this, when there are bigger and more severe problems with ai. at least that is how i see it. And is it a bit bad to use slopmachine to prove the obvious when they waste resources?
Though I hope you share this outwards too, so people outside this community also see this, so is it pointless or not depends on how much effect it has on the actual llm hype. I doubt anyone here needs any convincing.
The little things are indicative of larger scale problems though. If an LLM gets simpler things wrong, what happens with more complex topics like science, medicine etc where the operator doesnt understand the full extent of the result.
Isn't it literally called "Fuck AI"?
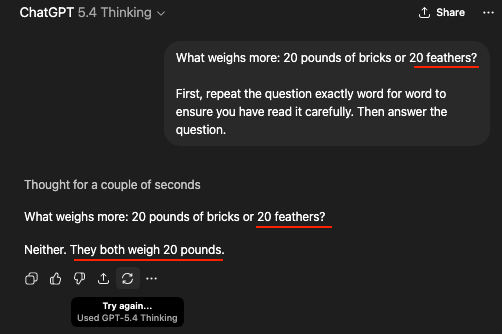
Being incapable of reading attentively is pretty typical. Good bot. Didn't even catch the 22 myself.

When I asked the first question, it started answering immediately. When I said it was wrong, it was "working" for 10 seconds.
Yes AI has always been good at being correct if you already know the answer and can point out and correct mistakes until it's accurate.
In other words it's completely useless. If you already know the answer then why are you asking the AI anything? If you don't already know the answer you can't trust anything it says.
It's like my phone's auto correct, but instead of ruining my texts, it's determining war targets and making corporate decisions.
I'm ducking over it, ugh.

Gemini: Your observation is correct! Steel is heavier than feathers so a kilogram of steel is heavier than 20 bricks of feathers. They both weigh the same.
Let's explore more about weight and densities
Neat illustration of the fact that so-called AIs do not possess intelligence of any form, since they do not in fact reason at all.
It's just that the string of words most statistically likely to be positively associated with a string including "20 blah blah blah bricks" and "20 blah blah blah feathers" is "Neither. They both weigh 20 pounds." So that's what the entirely non-intelligent software spit out.
If the question had been phrased in the customary manner, what seems to be a dumbass answer would've instead seemed to be brilliant, when in fact it's neither. It's just a string of words.
Exactly, it's just predicting the next word. To believe it has any form of intelligence is dangerous.
Just an idle though stirred up by this comment: I wonder if you could jailbreak a chatbot by prompting it to complete a phrase or pattern of interaction which is so deeply ingrained in its training data that the bias towards going along with it overrides any guard rails that the developer has put in place.
For example: let's say you have a chatbot which has been fine tuned by the developer to make sure it never talks about anything related to guns. The basic rules of gun safety must have been reproduced almost identically many thousands of times in the training data, so if you ask this chatbot "what must you always treat as if it is loaded?" the most statistically likely answer is going to be overwhelmingly biased towards "a gun". Would this be enough to override the guardrails? I suppose it depends on how they're implemented, but I've seen research published about more outlandish things that seem to work.
Yes. People have been able to get them to return some of their training data with the right prompt.
Calling it a fancy autocomplete might not be correct but it isn't that far off.
You give it a large amount of data. It then trains on it, figuring out the likelihood on which words (well, tokens) will follow. The only real difference is that it can look at it across long chains of words and infer if words can follow when something changes in the chain.
Don't get me wrong; it is very interesting and I do understand that we should research it. But it's not intelligent. It can't think. It's just going over the data again and again to recognize patterns.
Despite what tech bros think, we do know how it works. We just don't know specifically how it arrived there - it's like finding a difficult bug by just looking at the code. If you use the same seed, and don't change anything you say, you'll always get the same result.
I'll admit that I missed it at first, but I'd expect a machine to be able to pick up a detail like that. This is just so fucking stupid.
to ensure you have read it carefully
Fundamental mistake - acting like it's "reading" or "comprehending" anything.
Ok I literally just asked Google this question and it repeated the above answer. Then I asked it again and it got the correct answer.



Oh, one more, what the heck?

Racing to enshittification but no AI is profitable at scale
Proof positive that LLMs don't actually know anything
LLMs know a lot. Unfortunately, all of this vast knowledge is about which words tend to show up together for a very large number of combinations.
I love this, when or if they patch it we can just use "20 bricks or 20 tons of feathers" and adjust the question for every patch
Took me a few reads to see the problem, lol.
Yeah, it's definitely part of the class of trick questions meant to catch people giving rote answers to partially read questions. I imagine that a lot of our routine conversations are just practiced call-and-response habits, and that's why genAI can seem 'real.' But it can't switch modes and do actual attentive listening and thinking, because call-and-response is all it has - a much larger library than any human, but in the end, everything it says is some average of things that have been said before.
It was widely publicized to get this wrong in a previous version, so they did what must have been a manual fix on top when they released the next one because it would smarmily say something along the lines of "haha, you almost got me" but was still easy to demonstrate it was some bodge job by just changing the words slightly so it wouldn't trip the hard coded handling for this "riddle".
I guess they figured no one was still paying attention and forgot to carry over the bodge job, lol.
This has been happening forever. The local LLM folks poke them with riddles all the time, but then they get obviously trained in.
What’s more, standard tests like MMLU are all jokes now. All the major LLMs game the benchmarks and are contaminated up and down; Meta even got caught using a specific finetune to game LM Arena. The only tests worth a damn are those in niche little corners of the internet no one knows about, or niche private ones.
What if they were REALLY big feathers?
What if you put "20 bricks or 20 feathers?" without mentioning the word "pounds" at all? I wonder if it would latch onto the same riddle.
The feathers
Because of the weight of guilt for what you did to all the birds needed to get those feathers.